Mô hình Markov ẩn
Cũng tiện làm bài cuối kì tự dưng thấy cái Hidden Markov Model (HMM) này hay ho quá nên note lại vài dòng cho nhớ vậy
- Các dữ liệu quan sát được có liên hệ với nhau hay không?
- Mô hình Markov ẩn
- Các bài toán cơ bản của HMM
Khá là một cậu bé rất thông minh sinh ra trong một gia đình có truyền thống hiếu học vùng thôn dã, lớn lên trong một gia đình cần lao, giàu lòng yêu nước, sớm giác ngộ lý tưởng cách mạng. Tuổi trẻ thông minh đĩnh ngộ. Tương truyền mới sinh Khá không khóc không cười. Một hôm có vị đạo sĩ đi qua thấy Khá chơi trước cửa, liền nói: “Người này có dung mạo tọa thiên long, đầu gối sơn, chân đạp thủy, bên tả có thanh long, bên phải có bạch hổ, con nhà này chỉ mười tám năm sau, chắc chắn sẽ thành người lớn. Mọi người thấy vậy, cho là sự lạ, hết sức chăm sóc. Quả nhiên, Khá 6 tuổi đã đi học lớp 1, 8 tuổi đã đọc thông viết thạo, lên 9 tuổi đã biết cộng trừ nhân chia. Ai gặp cũng phải trầm trồ khâm phục. Giới học vấn uyên thâm, 18 tuổi đã xong tú tài, trên thông thiên văn, dưới tường địa lý, giữa hiểu nhân luân, ai hỏi gì cũng trả lời được, tuyệt nhiên không đúng câu nào. Đến năm 20 tuổi Khá lui về ở ẩn. Thăm thú sự đời, thấy việc gì có lợi là làm. Nợ nần không biết bao nhiêu mà kể!”.
Tương truyền lúc còn hành tẩu trong ao hồ, Khá có đem lòng yêu con gái của Huấn đại hiệp - một vị học giả uyên thâm, mà minh chứng là những triết lí cuộc sống, những lời răn dạy qua những trang sách. Để chinh phục trái tim của nàng, Khá mỗi ngày gửi cho nàng những áng thơ tình tuyệt tác, những lời yêu có cánh cùng những lời hứa hẹn về một tương lai xán lạn. Tuy nhiên, không phải lúc nào Khá cũng nhận được thư hồi âm của nàng, điều này làm Khá cảm thấy buồn bực. Khá quyết tâm tìm cho ra lí do đằng sau việc không hồi âm của nàng.
Các dữ liệu quan sát được có liên hệ với nhau hay không?
Đầu tiên, Khá cho rằng các lần nàng hồi âm cho Khá có liên hệ với nhau, tuy nhiên sau nhiều nỗ lực điều tra, Khá vẫn không có chút manh mối nào cho vấn đề này. Mất rất nhiều thời gian và tiền bạc nhưng không đem lại kết quả làm Khá rất buồn bực. May thay, gần đây giang hồ truyền nhau về một vị học thật tên là Dũng, tiếng tăm nồng nặc, học vấn uyên thâm, võ công cái thế lại có tài ăn nói, duy chỉ hay bốc phét là chưa ưng, đến thăm thành phố, Khá bèn đến và nhờ giúp đỡ.
Nghe xong, vị học thật này phán rằng:
Nữ nhân tuy rằng khó hiểu, tuy nhiên phàm là người trong thiên hạ, không gì không thể thông hiểu. Cậu tuy tuổi còn nhỏ, nhưng có tinh thần học hỏi, lại cũng là người thông minh, ta không thể không giúp. Ta chỉ nói một câu thôi: “Có nguyên nhân đứng sau chi phối việc gửi thư của vị nữ nhân này, ngươi nên tìm hiểu cho kĩ”
Dứt lời, vị học thật này biến mất.
Khá cùng các môn đệ đứng đó vái lạy một hồi rồi trầm ngâm suy nghĩ.
Nói linh tinh một chút, ta quay lại với bài toán gốc.
Điều gì xảy ra nếu có nguyên nhân đứng phía sau chi phối việc hồi âm của vị nữ hiệp kia?
Có rất nhiều nguyên nhân, mà chỉ có vị nữ tử kia biết. Để cho đơn giản, ta hãy giả định như sau:
- Vui \(\to\) trả lời
- Buồn \(\to\) không trả lời
Như vậy, việc trả lời thư cho Khá phụ thuộc vào tâm trạng của nàng. Tuy nhiên, nếu có những hôm vui nhưng nàng vẫn gửi thư cho Khá, và những hôm vui mà nàng lại không gửi thư thì sao?
Ta sẽ lại có một chút thay đổi như sau

Thế thì mối quan hệ giữa vui và không vui là gì?
Các cụ có câu: "Sáng nắng chiều mưa,giữa trưa có bão", rõ ràng tâm trạng của nàng làm một quá trình ngẫu nhiên. Ta biết rằng quá trình chuyển trạng thái có thể được mô hình hóa bởi một xích Markov, tức là xích Markov này có không gian trạng thái \(S=\{\text{vui, không vui}\}\) và ma trận xác suất chuyển \(A\), mà ở đây là chưa biết.
Như vậy mô hình đầy đủ cho quá trình này có thể được minh họa như sau
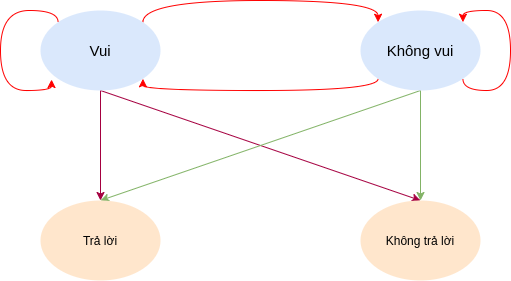
Dĩ nhiên là ta chưa thể biết được quy luật thay đổi trạng thái cũng như xác suất vị nữ nhân này có trả lời hay không, ta sẽ tìm hiểu ở phần sau.
Một mô hình như trên được gọi là mô hình Markov ẩn.
Mô hình Markov ẩn

Trên đây là một mô hình tương đối chính xác về quá trình phát triển của một mô hình Markov ẩn
Định nghĩa
Những kiến thức cơ bản nhất về xích Markov đã được đề cập đến trong các bài viết trước, do đó bài này sẽ không nhắc lại nữa. Ta sẽ đến trực tiếp định nghĩa của một xích Markov ẩn
Mô hình Markov ẩn được xác định bởi các yếu tố sau:
- Chuỗi các quan sát \(O=\left(o_{1},o_{2},...,o_{n},...\right)\)
- Tập các trạng thái \(S=\left\{ s_{1},s_{2},...,s_{n}\right\}\)
- Ma trận xác suất chuyển \(A\) của các trạng thái thuộc \(S: A=\left(a_{ij}\right)\)
- Ma trận xác suất phụ thuộc trạng thái \(B = (p_{i}(o_i))\)
- Phân phối ban đầu \(\pi\)
Dừng ở đây, chúng ta sẽ cần phân tích một chút về cấu tạo của một xích Markov ẩn.
Các thành phần
Các quan sát
Các quan sát ban đầu là một dãy các dữ liệu thu được \(O=\left(o_{1},o_{2},...,o_{n}\right)\) thu thập được dựa trên các quan sát thực tế. Dĩ nhiên các quan sát này có thể chả có liên quan gì đến nhau cả.
Các quan sát ở đây chính là thư hồi âm của người trong mộng cho Khá.
Xích Markov ẩn
Phần xích Markov ẩn này thực chất chính là xích Markov đã được đề cập trước đó trong các bài viết trước, vẫn bao gồm 3 thành phần.
Không gian trạng thái
Không gian trạng thái \(S\) là tập các trạng thái có thể của xích Markov.
Dĩ nhiên không gian trạng thái này cho ta biết trạng thái hiện tại của xích Markov, tuy nhiên không phản ánh được các tính chất của xích.
Đối với bài toán trên, \(S=\{\text{vui, không vui}\}\)
Ma trận xác suất chuyển
Ma trận \(A\) là ma trận thể hiện cho mối quan hệ giữa các trạng thái
Đây là yếu tố không thể thiếu cho một xích Markov.
Dĩ nhiên, nếu không cho không gian trạng thái, ta có thể gọi đại diện \(s_1,s_2,...\) Tuy nhiên nếu không cho ma trận xác suất chuyển \(A\) thì các trạng thái được cho là vô nghĩa.
Phân phối ban đầu
Một yếu tố cũng quan trọng không kém là phân phối ban đầu \(\pi\) của xích Markov.
Phân phối ban đầu không thể hiện quan hệ giữa các trạng thái, tuy nhiên nó cho chúng ta biết khả năng các sự kiện xảy ra tại thời điểm \(t=0\).
Khi có phân phối ban đầu ta có thể xác định được một dãy các trạng thái sau \(n\) thời điểm có khả năng xảy ra cao nhất. Phần này sẽ được nhắc đến sau.
Phân phối phụ thuộc trạng thái
Trong mô hình Markov ẩn, ta giả sử rằng các quan sát đóng vai trò là biểu hiện của các trạng thái ẩn phía sau, do đó việc có được quan hệ giữa biểu hiện của trạng thái và trạng thái đó là cần thiết.
Tại thời điểm \(t=i\), xích Markov \(H\) đang ở trạng thái \(h_t = i\), ta có xác suất để quan sát nhận giá trị \(j\) là
\[P\left[o_{i}\mid o_{1},o_{2},...,o_{i},...,o_{T},h_{1},h_{2},...,h_{i},...,h_{T}\right]=P\left[o_{i}\mid h_{i}\right]\]được gọi là phân phối phụ thuộc trạng thái, (emission probability, state-dependent distribution).
Trong bài, phân phối này là xác suất mà con gái Huấn đại hiệp chọn trả lời hay không trả lời phụ thuộc vào tâm trạng của nàng.
Các bài toán cơ bản của HMM
HMM có tính ứng dụng rất cao trong rất nhiều các lĩnh vực, tuy nhiên chúng ta có thể chia ra được ba vấn đề chính đối với mô hình HMM
Likelihood
Cho mô hình Markov ẩn \(\lambda=\left(\pi,A,B\right)\) và dãy các quan sát \(O\), hãy tính xác suất xảy ra dãy quan sát trên với mô hình HMM \(\lambda\), hay nói cách khác, cần tính \(P[O\mid\lambda]\)
Với mô hình HMM \(\lambda=\left(\pi,A,B\right)\) và chuỗi các quan sát \(O=(o_{1},o_{2},...,o_{T-1})\). Việc cần tính ở đây là \(P[O\mid\lambda]\).
Gọi \(H=\left(h_{0},h_{1},...,h_{T-1}\right)\) là chuỗi các trạng thái của xích Markov. Khi đó theo định nghĩa \(B\) bên trên, ta có:
\[P\left[O\mid H,\lambda\right]=p_{x_{0}}\left(O_{0}\right)p_{x_{1}}\left(O_{1}\right)...p_{x_{T-1}}\left(O_{T-1}\right)\]và theo định nghĩa của \(\pi\) là phân phối ban đầu và \(A\) là ma trận xác suất chuyển ta có:
\[P\left[H\mid \lambda\right]=\pi_{h_{0}}a_{h_{0}}a_{h_{1},h_{2}}...a_{h_{T-2},h_{T-1}}\]Theo Bayes, ta có:
\[P\left(O,H\mid \lambda\right)=\frac{P\left(O,H,\lambda\right)}{P\left(\lambda\right)}\]và lại có:
\[P\left(O\mid H,\lambda\right)P\left(H\mid \lambda\right)=\frac{P\left(O,H,\lambda\right)}{P\left(H,\lambda\right)}.\frac{P\left(H,\lambda\right)}{P\left(\lambda\right)}=\frac{\left(O,H,\lambda\right)}{P\left(\lambda\right)}\]Do đó ta có:
\[P\left(O,H\mid \lambda\right)=P\left(O\mid H,\lambda\right)P\left(H\mid \lambda\right)\]Theo công thức xác suất đầy đủ, ta có:
\[\begin{aligned} P\left(O\mid \lambda\right) & =\sum_{H}P\left(O,H\mid \lambda\right)\\ & =\sum_{H}P\left(O\mid H,\lambda\right)P\left(H\mid \lambda\right)\\ & =\sum_{H}\pi_{h_{0}}p_{h_{0}}\left(O_{0}\right)a_{h_{0},h_{1}}b_{h_{1}}\left(O_{1}\right)...a_{h_{T-2},h_{T-1}}b_{h_{T-1}}\left(O_{T-1}\right) \end{aligned}\]Tính toán trên là có thể thực hiện được, tuy nhiên với \(2TN^T\) phép nhân, việc này trở nên rất khó khăn và do đó, chúng ta cần có một thuật toán hiệu quả hơn.
Để tính \(P\left[O\mid\lambda\right]\), ta có thuật toán forward algorithm. Với \(t=0,1,...,T-1\) và \(i=0,1,2,...,N-1\), ta có
Khi đó, \(\alpha_{t}\left(i\right)\) là xác suất của chuỗi các quan sát cho đến thời điểm \(t\), trong đó tại thời điểm \(t\), xích Markov ẩn đang ở trạng thái \(h_i\).
Khi đó \(\alpha_{t}\left(i\right)\) có thể được tính một cách đệ quy như sau:
- Đặt \(\alpha_{t}\left(i\right)=\pi_{i}b_{i}\left(O_{0}\right),i=0,1,...,N-1\)
-
Với \(t=0,1,...,T-1\) và \(i=0,1,2,...,N-1\), ta tính
\[\alpha_{t}\left(i\right)=\left[\sum_{j=0}^{N-1}\alpha_{t-1}\left(j\right)a_{ji}\right]p_{i}\left(O_{t}\right)\] - Khi đó ta có: \(P\left(O\mid \lambda\right)=\sum_{i=0}^{N-1}\alpha_{T-1}\left(i\right)\)
Thuật toán này chỉ cần thực hiện \(N^2T\) phép nhân, rõ ràng tốt hơn rất nhiều so với \(2TN^T\) của cách tiếp cận thông thường.
Decoding
Cho dãy các quan sát \(O\) và mô hình \(\lambda=\left(A,B\right)\), xác định dãy trạng thái phù hợp nhất với dãy quan sát trên. Như đã đề cập, có thể có rất nhiều phương án hợp lí nhất. Với mô hình Markov ẩn, ta sẽ muốn cực đại số lượng trạng thái chính xác. Mặt khác, một chương trình quy hoạch động (dynamic program) sẽ tìm điểm số cao nhất của mỗi path. Như đã thấy, đáp án đưa ra của hai thuật toán trên có thể không giống nhau.
Đầu tiên, ta định nghĩa backward algorithm. Thuật toán này tương tự với forward algorithm đã đề cập ở trên, chỉ khác lại là thuật toán này bắt đầu từ trạng thái cuối cùng và tính toán ngược về điểm bắt đầu.
Với \(t=0,1,...,T-1\) và \(i=0,1,...,N-1\), ta xác định
\[\beta_{t}\left(i\right)=P\left(O_{t+1},O_{t+2},...,O_{T-1}\mid h_{t}=s_{i},\lambda\right)\]Khi đó \(\beta_t(i)\) có thể được tính một cách đệ quy như sau:
- Đặt \(\beta_{T-1}\left(i\right)=1,i=0,1,...,N-1\).
-
Với \(t=0,1,...,T-1\) và \(i=0,1,2,...,N-1\) ta tính
\[\beta_{t}\left(i\right)=\sum_{j=0}^{N-1}a_{ij}b_{j}\left(O_{t+1}\right)\beta_{t+1}\left(j\right)\]Với \(t=0,1,...,T-1\) và \(i=0,1,...,N-1\) ta xác định:
\[\gamma_{t}\left(i\right)=P\left(h_{t}=s_{i}\mid O,\lambda\right)\]
Từ \(\alpha_{t}\left(i\right)\) tính xác suất cho đến thời điểm \(t\) và \(\beta_{T-1}\left(i\right)\) tính toán xác suất từ thời điểm \(T-1\) ngược về thời điểm \(t\), do đó ta có:
\[\gamma_{t}\left(i\right)=\frac{\alpha_{t}\left(i\right)\beta_{t}\left(i\right)}{P\left(O\mid \lambda\right)}\]Nhắc lại rằng mẫu số \(P\left(O\mid \lambda\right)\) được tính bằng cách lấy tổng theo \(i\) của \(\alpha_{T-1}\left(i\right)\). Từ định nghĩa của \(\gamma_t(i)\), ta thấy rằng trạng thái hợp lí nhất tại thời điểm \(t\) là trạng thái \(h_i\) mà trong đó \(\gamma_t(i)\) đạt giá trị lớn nhất, với cực đại được lấy theo chỉ số \(i\).
Learning
Cho dãy các quan sát \(O\) và tập các trạng thái của xích Markov ẩn, xác định các tham số của \(A\) và \(B\). Hiển nhiên đây là trường hợp chúng ta gặp rất nhiều: cho quan sát, xác định mô hình cho quá trình đó.
Đối với bài toán này, ta giả định đã biết được số trạng thái của quan sát \(M\) và số trạng thái của xích Markov ẩn \(N\), và ta cần xác định \(\pi, A, B\) tương ứng. Một trong những sự thật thú vị về HMM là mô hình của chúng ta có thể tự ước lượng các tham số của nó.
Với \(t=0,1,...,T-2\) và \(i,j \in \{0,1,...,N-1\}\), ta định nghĩa
\[\gamma_{t}\left(i,j\right)=P\left[h_{t}=s_{i},h_{t+1}=s_{j}\mid O,\lambda\right]\]Khi đó \(\gamma_t(i,j)\) là xác suất xích ở trạng thái \(s_i\) tại thời điểm \(t\) và chuyển sang \(s_j\) tại thời điểm \(t+1\). \(\gamma_t(i,j)\) có thể được biểu diễn bởi \(\alpha,\beta,A\) và \(B\) như sau:
\[\gamma_{t}\left(i,j\right)=\frac{\alpha_{t}\left(i\right)a_{ij}p_{j}\left(O_{t+1}\right)\beta_{t+1}\left(j\right)}{P\left(O\mid \lambda\right)}\]Với \(t=0,1,2,...,T-2\), ta xác định quan hệ giữa \(\gamma_t(i)\) và \(\gamma_t(i,j)\) như sau:
\[\gamma_{t}\left(i\right)=\sum_{j=0}^{N-1}\gamma_{t}\left(i,j\right)\]Với \(\gamma\) và \(\gamma(i,j)\) đã có như trên, ta có thể ước lượng mô hình \(\lambda=(\pi, A, B)\) theo quy trình sau
-
Với \(i=0,1,2,...,N-1\), đặt \(\pi_i = \gamma_0(i)\)
-
Với \(i=0,1,...,N-1\) và \(j=0,1,...,N-1\), tính \(a_{ij}=\frac{\sum_{t=0}^{T-2}\gamma_{t}\left(i,j\right)}{\sum_{t=0}^{T-2}\gamma_{t}\left(i\right)}\)
-
Với \(j=0,1,...,N-1\) và \(k=0,1,...,M-1\) ta tính \(p_{j}\left(k\right)=\sum_{t\in\left\{ 0,1,...,T-1\right\} ,O_{t=k}}\gamma_{t}\left(j\right)\big\backslash\sum_{t=0}^{T-1}\gamma_{t}\left(j\right)\)
Trong ước lượng của \(a_{ij}\), phần tử số cho ta kì vọng của số lần xích chuyển từ trạng thái \(s_i \to s_j\), trong khi đó mẫu số cho ta kì vọng của số lần xích chuyển từ trạng thái \(s_i\) sang tất cả các trạng thái. Tỉ lệ này là xác suât chuyển từ trạng thái \(s_i\) sang trạng thái \(s_j\), cho ta một ước lượng của \(a_{ij}\).
Đối với ước lượng của \(b_{ij}\), phần tử số cho ta kì vọng về số lần xích ẩn ở trạng thái \(s_j\) với quan sát \(k\), trong khi đó mẫu số là kì vọng của số lần xích ở trạng thái \(s_j\). Tỉ lệ này chính là xác suất của quan sát \(k\) khi xích ẩn của mô hình đang ở trạng thái \(s_j\), là một ước lượng cho \(p_j(k)\).
Quá trình ước lượng này là một quá trình lặp. Đầu tiên, ta khởi tạo \(\lambda=(\pi, A, B)\) một cách ngẫu nhiên. Rõ ràng rằng \(A, B, \pi\) là ngẫu nhiên, do đó kết quả của quá trình ước lượng này sẽ là một nghiệm tối ưu địa phương. Không có gì đảm bảo được \(A, B, \pi\) là nghiệm tối ưu toàn cục, mà trong thực tế, việc tìm được nghiệm tối ưu địa phương cũng có thể được coi là tốt.
Tóm lại, bài toán này có thể được tóm tắt lại như sau:
- Khởi tạo \(\lambda=(\pi, A, B)\).
- Tính các giá trị \(\alpha_{t}\left(i\right),\beta_{t}\left(i\right),\gamma_{t}\left(i,j\right),\gamma_{t}\left(i\right)\).
- Ước lượng lại mô hình \(\lambda=(\pi, A, B)\).
- Nếu \(P(O\mid \lambda)\) tăng lên, quay trở lại bước 2
Hiển nhiên rằng chúng ta cũng nên quyết định thuật toán sẽ dừng khi nào, ví dụ như thay đổi giữa các vòng lặp trở nên không đáng kể, hoặc đã đạt đến số vòng lặp tối đa cho phép.
Ơ thế vị học thật này dài dòng thế, tóm lại ông có tán được con gái Huấn đại hiệp không?
Phần áp dụng trên bộ dữ liệu thật khá dài, vì thế nên mình sẽ để dành đến bài viết sau. Bài viết sau sẽ trình bày cụ thể hơn về phần cài đặt thuật toán và đưa ra chiến lược chinh phục vị nữ tử cưng của Huấn đại hiệp.
Chào các bậc hảo hán, chúc các vị đưa ra được chiến lược chinh phục người phụ nữ của mình.